
Easily add logs to your functions, without interfering with the global environment.
You can install the development version from GitHub with:
# install.packages("devtools")
devtools::install_github("b-rodrigues/chronicler"){chronicler} provides the record()
function, which allows you to modify functions so that they provide
enhanced output. This enhanced output consists in a detailed log, and by
chaining decorated functions, it becomes possible to have a complete
trace of the operations that led to the final output. These decorated
functions work exactly the same as their undecorated counterparts, but
some care is required for correctly handling them. This introduction
will give you a quick overview of this package’s functionality.
Let’s first start with a simple example, by decorating the
sqrt() function:
library(chronicler)
r_sqrt <- record(sqrt)
a <- r_sqrt(1:5)Object a is now an object of class
chronicle. Let’s take a closer look at a:
a
#> OK! Value computed successfully:
#> ---------------
#> Just
#> [1] 1.000000 1.414214 1.732051 2.000000 2.236068
#>
#> ---------------
#> This is an object of type `chronicle`.
#> Retrieve the value of this object with pick(.c, "value").
#> To read the log of this object, call read_log(.c).a is now made up of several parts. The first part:
OK! Value computed successfully:
---------------
Just
[1] 1.000000 1.414214 1.732051 2.000000 2.236068simply provides the result of sqrt() applied to
1:5 (let’s ignore the word Just on the third
line for now; for more details see the Maybe Monad
vignette). The second part tells you that there’s more to it:
---------------
This is an object of type `chronicle`.
Retrieve the value of this object with pick(.c, "value").
To read the log of this object, call read_log().The value of the sqrt() function applied to its
arguments can be obtained using pick(), as explained:
pick(a, "value")
#> [1] 1.000000 1.414214 1.732051 2.000000 2.236068A log also gets generated and can be read using
read_log():
read_log(a)
#> [1] "Complete log:"
#> [2] "OK! sqrt() ran successfully at 2022-05-13 09:48:04"
#> [3] "Total running time: 0.000597000122070312 secs"This is especially useful for objects that get created using multiple calls:
r_sqrt <- record(sqrt)
r_exp <- record(exp)
r_mean <- record(mean)
b <- 1:10 |>
r_sqrt() |>
bind_record(r_exp) |>
bind_record(r_mean)(bind_record() is used to chain multiple decorated
functions and will be explained in detail in the next section.)
read_log(b)
#> [1] "Complete log:"
#> [2] "OK! sqrt() ran successfully at 2022-05-13 09:48:04"
#> [3] "OK! exp() ran successfully at 2022-05-13 09:48:04"
#> [4] "OK! mean() ran successfully at 2022-05-13 09:48:04"
#> [5] "Total running time: 0.0292508602142334 secs"
pick(b, "value")
#> [1] 11.55345record() works with any function, but not yet with
{ggplot2}.
To avoid having to define every function individually, like this:
r_sqrt <- record(sqrt)
r_exp <- record(exp)
r_mean <- record(mean)you can use the record_many() function.
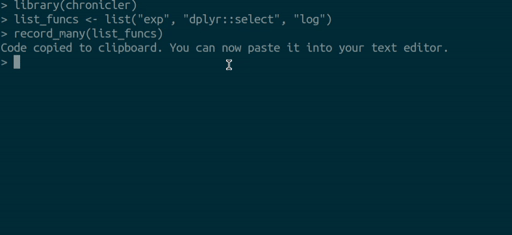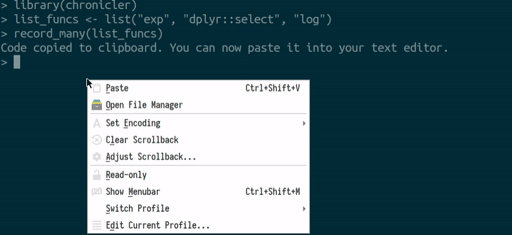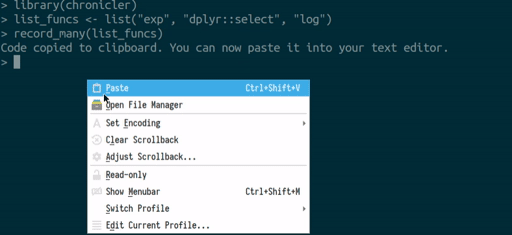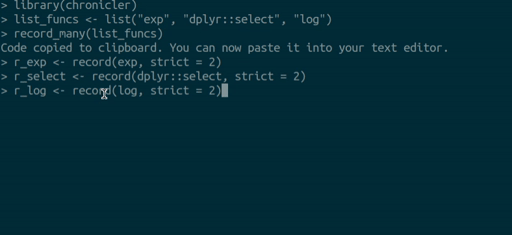
record_many() takes a list of functions (as strings) as an
input and puts generated code in your system’s clipboard. You can then
paste the code into your text editor. The gif below illustrates how
record_many() works:
bind_record() is used to pass the output from one
decorated function to the next:
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
r_group_by <- record(group_by)
r_select <- record(select)
r_summarise <- record(summarise)
r_filter <- record(filter)
output <- starwars %>%
r_select(height, mass, species, sex) %>%
bind_record(r_group_by, species, sex) %>%
bind_record(r_filter, sex != "male") %>%
bind_record(r_summarise,
mass = mean(mass, na.rm = TRUE)
)read_log(output)
#> [1] "Complete log:"
#> [2] "OK! select(height,mass,species,sex) ran successfully at 2022-05-13 09:48:04"
#> [3] "OK! group_by(species,sex) ran successfully at 2022-05-13 09:48:04"
#> [4] "OK! filter(sex != \"male\") ran successfully at 2022-05-13 09:48:04"
#> [5] "OK! summarise(mean(mass, na.rm = TRUE)) ran successfully at 2022-05-13 09:48:04"
#> [6] "Total running time: 0.250557899475098 secs"The value can then be accessed and worked on as usual using
pick(), as explained above:
pick(output, "value")
#> # A tibble: 9 × 3
#> # Groups: species [9]
#> species sex mass
#> <chr> <chr> <dbl>
#> 1 Clawdite female 55
#> 2 Droid none 69.8
#> 3 Human female 56.3
#> 4 Hutt hermaphroditic 1358
#> 5 Kaminoan female NaN
#> 6 Mirialan female 53.1
#> 7 Tholothian female 50
#> 8 Togruta female 57
#> 9 Twi'lek female 55This package also ships with a dedicated pipe, %>=%
which you can use instead of bind_record():
output_pipe <- starwars %>%
r_select(height, mass, species, sex) %>=%
r_group_by(species, sex) %>=%
r_filter(sex != "male") %>=%
r_summarise(mean_mass = mean(mass, na.rm = TRUE))pick(output_pipe, "value")
#> # A tibble: 9 × 3
#> # Groups: species [9]
#> species sex mean_mass
#> <chr> <chr> <dbl>
#> 1 Clawdite female 55
#> 2 Droid none 69.8
#> 3 Human female 56.3
#> 4 Hutt hermaphroditic 1358
#> 5 Kaminoan female NaN
#> 6 Mirialan female 53.1
#> 7 Tholothian female 50
#> 8 Togruta female 57
#> 9 Twi'lek female 55Using the %>=% is not recommended in non-interactive
sessions. When using {chronicler} non-interactively (for
example, using Rscript or {targets}), using
bind_record() to chain functions is recommended.
By default, errors and warnings get caught and composed in the log:
errord_output <- starwars %>%
r_select(height, mass, species, sex) %>=%
r_group_by(species, sx) %>=% # typo, "sx" instead of "sex"
r_filter(sex != "male") %>=%
r_summarise(mass = mean(mass, na.rm = TRUE))errord_output
#> NOK! Value computed unsuccessfully:
#> ---------------
#> Nothing
#>
#> ---------------
#> This is an object of type `chronicle`.
#> Retrieve the value of this object with pick(.c, "value").
#> To read the log of this object, call read_log(.c).Reading the log tells you which function failed, and with which error message:
read_log(errord_output)
#> [1] "Complete log:"
#> [2] "OK! select(height,mass,species,sex) ran successfully at 2022-05-13 09:48:04"
#> [3] "NOK! group_by(species,sx) ran unsuccessfully with following exception: Must group by variables found in `.data`.\n✖ Column `sx` is not found. at 2022-05-13 09:48:04"
#> [4] "NOK! filter(sex != \"male\") ran unsuccessfully with following exception: Pipeline failed upstream at 2022-05-13 09:48:05"
#> [5] "NOK! summarise(mean(mass, na.rm = TRUE)) ran unsuccessfully with following exception: Pipeline failed upstream at 2022-05-13 09:48:05"
#> [6] "Total running time: 0.118661165237427 secs"It is also possible to only capture errors, or capture errors,
warnings and messages using the strict parameter of
record()
# Only errors:
r_sqrt <- record(sqrt, strict = 1)
r_sqrt(-10) |>
read_log()
#> Warning in .f(...): NaNs produced
#> [1] "Complete log:"
#> [2] "OK! sqrt() ran successfully at 2022-05-13 09:48:05"
#> [3] "Total running time: 0.000468969345092773 secs"
# Errors and warnings:
r_sqrt <- record(sqrt, strict = 2)
r_sqrt(-10) |>
read_log()
#> [1] "Complete log:"
#> [2] "NOK! sqrt() ran unsuccessfully with following exception: NaNs produced at 2022-05-13 09:48:05"
#> [3] "Total running time: 0.000579833984375 secs"
# Errors, warnings and messages
my_f <- function(x){
message("this is a message")
10
}
record(my_f, strict = 3)(10) |>
read_log()
#> [1] "Complete log:"
#> [2] "NOK! my_f() ran unsuccessfully with following exception: this is a message\n at 2022-05-13 09:48:05"
#> [3] "Total running time: 0.000589132308959961 secs"You can provide a function to record(), which will be
evaluated on the output. This makes it possible to, for example, monitor
the size of a data frame throughout the pipeline:
r_group_by <- record(group_by)
r_select <- record(select, .g = dim)
r_summarise <- record(summarise, .g = dim)
r_filter <- record(filter, .g = dim)
output_pipe <- starwars %>%
r_select(height, mass, species, sex) %>=%
r_group_by(species, sex) %>=%
r_filter(sex != "male") %>=%
r_summarise(mass = mean(mass, na.rm = TRUE))The $log_df element of a chronicle object
contains detailed information:
pick(output_pipe, "log_df")
#> # A tibble: 4 × 11
#> ops_number outcome `function` arguments message start_time
#> <int> <chr> <chr> <chr> <chr> <dttm>
#> 1 1 OK! Success select "height,mass,sp… NA 2022-05-13 09:48:05
#> 2 2 OK! Success group_by "species,sex" NA 2022-05-13 09:48:05
#> 3 3 OK! Success filter "sex != \"male\… NA 2022-05-13 09:48:05
#> 4 4 OK! Success summarise "mean(mass, na.… NA 2022-05-13 09:48:05
#> # … with 5 more variables: end_time <dttm>, run_time <drtn>, g <list>,
#> # diff_obj <list>, lag_outcome <chr>It is thus possible to take a look at the output of the function
provided (dim()) using check_g():
check_g(output_pipe)
#> ops_number function g
#> 1 1 select 87, 4
#> 2 2 group_by NA
#> 3 3 filter 23, 4
#> 4 4 summarise 9, 3We can see that the dimension of the dataframe was (87, 4) after the
call to select(), (23, 4) after the call to
filter() and finally (9, 3) after the call to
summarise().
Another possibility for advanced logging is to use the
diff argument in record, which defaults to “none”. Setting
it to “full” provides, at each step of a workflow, the diff between the
input and the output:
r_group_by <- record(group_by)
r_select <- record(select, diff = "full")
r_summarise <- record(summarise, diff = "full")
r_filter <- record(filter, diff = "full")
output_pipe <- starwars %>%
r_select(height, mass, species, sex) %>=%
r_group_by(species, sex) %>=%
r_filter(sex != "male") %>=%
r_summarise(mass = mean(mass, na.rm = TRUE))Let’s compare the input and the output to
r_filter(sex != "male"):
# The following line generates a data frame with columns `ops_number`, `function` and `diff_obj`
# it is possible to filter on the step of interest using the `ops_number` or the `function` column
diff_pipe <- check_diff(output_pipe)
diff_pipe %>%
filter(`function` == "filter") %>% # <- backticks around `function` are required
pull(diff_obj)
#> [[1]]
#> < input
#> > output
#> @@ 1,15 / 1,15 @@
#> < # A tibble: 87 × 4
#> > # A tibble: 23 × 4
#> < # Groups: species, sex [41]
#> > # Groups: species, sex [9]
#> height mass species sex
#> <int> <dbl> <chr> <chr>
#> < 1 172 77 Human male
#> 2 167 75 Droid none
#> 3 96 32 Droid none
#> < 4 202 136 Human male
#> 5 150 49 Human female
#> < 6 178 120 Human male
#> 7 165 75 Human female
#> 8 97 32 Droid none
#> > 6 175 1358 Hutt hermaphroditic
#> > 7 200 140 Droid none
#> < 9 183 84 Human male
#> > 8 150 NA Human female
#> < 10 182 77 Human male
#> > 9 163 NA Human female
#> > 10 178 55 Twi'lek female
#> < # … with 77 more rows
#> > # … with 13 more rowsIf you are familiar with the version control software
Git, you should have no problem reading this output. The
input was a data frame of 87 rows and 4 columns, and the output only had
23 rows. Rows that were in the input, and got removed from the output,
are highlighted (in the terminal, but not here, due to the color
scheme). If diff is set to “summary”, then only a summary
is provided:
r_group_by <- record(group_by)
r_select <- record(select, diff = "summary")
r_summarise <- record(summarise, diff = "summary")
r_filter <- record(filter, diff = "summary")
output_pipe <- starwars %>%
r_select(height, mass, species, sex) %>=%
r_group_by(species, sex) %>=%
r_filter(sex != "male") %>=%
r_summarise(mass = mean(mass, na.rm = TRUE))
diff_pipe <- check_diff(output_pipe)
diff_pipe %>%
filter(`function` == "filter") %>% # <- backticks around `function` are required
pull(diff_obj)
#> [[1]]
#>
#> Found differences in 5 hunks:
#> 8 insertions, 8 deletions, 7 matches (lines)
#>
#> Diff map (line:char scale is 1:1 for single chars, 1:1 for char seqs):
#> DDII..D..D.D..DDDIIIIIIBy combining .g and diff, it is possible to
have a very clear overview of what happened to the very first input
throughout the pipeline. diff functionality is provided by
the {diffobj} package.
I’d like to thank armcn, Kupac for their blog posts (here)
and packages (maybe) which
inspired me to build this package. Thank you as well to TimTeaFan
for his help with writing the %>=% infix operator, nigrahamuk
for showing me a nice way to catch errors, and finally Mwavu
for pointing me towards the right direction with an issue I’ve had as I
started working on this package. Thanks to Putosaure for designing the hex
logo.